System Design — Rate Limiter

What is a rate limiter?
A rate limiter, as the name suggests, puts a limit on the number of requests a service fulfills. It throttles requests that cross the predefined limit.
Why do we need a rate limiter?
- Preventing resource starvation: One of the common use cases of rate limiters is to avoid resource starvation caused by such denial of service attacks, whether intentional or unintentional.
- Managing policies and quotas: to provide a fair and reasonable use of resources’ capacity when they are shared among many users. The policy refers to applying limits on the time duration or quantity allocated (quota).
- Controlling data flow: Rate limiters control the flow of data to distribute the work evenly among different machines, avoiding the burden on a single machine.
- Avoiding excess costs: to control the cost of operations. For example, organizations can use rate limiting to prevent experiments from running out of control and avoid large bills. Some cloud service providers also use this concept by providing freemium services to certain limits, which can be increased on request by charging from users.

High-Level Design of Rate Limiter
- Client-side implementation: it would be easy for someone with malicious intent to forge or bypass the rate limiter.
- Server-side implementation:

There is alternative to the client and server-side implementations. We construct a rate limiter middleware, which throttles requests to your APIs, rather than establishing a rate limiter on the API servers, as indicated in the diagram below.

We need a counter at the highest level to track how many requests are submitted from the same user, IP address, etc. The request is rejected if the counter exceeds the limit. We can use Redis for the counter.

Types of Throttling
- Hard Throttling: The number of API requests cannot exceed the throttle limit.
- Soft Throttling: In this type, we can set the API request limit to exceed a certain percentage. For example, if we have a rate limit of 100 messages a minute and 10% exceeds the limit, our rate limiter will allow up to 110 messages per minute.
- Elastic or Dynamic Throttling: Under Elastic throttling, the number of requests can go beyond the threshold if the system has some resources available. For example, if a user is allowed only 100 messages a minute, we can let the user send more than 100 messages a minute when there are free resources available in the system.
Rate Limiting Algorithms
There are several techniques for measuring and limiting rates, each with its own uses and implications.
- Token Bucket Algorithm
Each API request consumes one token. When a request arrives, we check if there is at least one token left in the bucket. If there is, we take one token out of the bucket, and the request goes through. If the bucket is empty, the request is dropped.

Example:
- In the above example, there is a limit of 3 requests per minute per user.
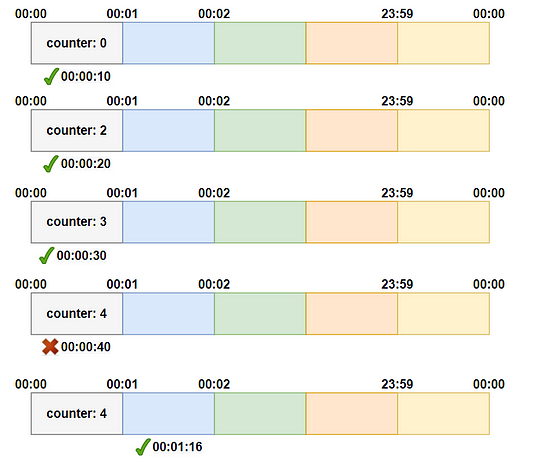
- User 1 makes the first request at 10:00:00; the available token is 3, therefore the request is approved, and the available token count is reduced to 2.
- At 10:00:10, the user’s second request, the available token is 2, the request is permitted, and the token count is decremented to 1.
- The third request arrives at 10:00:35, with token count 1 available, therefore the request is granted and decremented.
- The 4th request will arrive at 10:00:45, and the available count is already zero, hence API is denied.
- Now, at 10:01:00, the count will be refreshed with the available token 3 for the third time.
Pros:
- simple and easy to implement.
- very memory efficient.
Cons:
- A race condition, as described above, may cause an issue in a distributed system due to concurrent requests from the same user. We have discussed above how to avoid this situation.
2. Leaky Bucket Algorithm
Similar to the token bucket, however, instead of tokens, it is filled with requests from that client. Requests are taken out of the bucket and processed at a constant rate. If the rate at which requests arrive is greater than the rate at which requests are processed, the bucket will fill up and further requests will be dropped until there is space in the bucket.
In Leaky Bucket algorithm bucket size is equal to the queue size. The queue holds the requests to be processed at a fixed rate.

As you can see, just 3 requests/user is allowed and the Queue size is 3, the API rate limiter will block the 4th Request.
Algorithm:
For each request a user makes,
- Check if the queue limit is exceeded.
- if the queue limit has been exceeded, the request is dropped
- Otherwise, we add requests to the queue end and handle the incoming request.
Pros:
- Memory is efficient given the limited queue size.
- Requests are processed at a fixed rate, therefore it is suitable for use cases where a stable outflow rate is required.
Cons:
- A burst of traffic fills up the queue with old requests, and if they are not processed in time, recent requests will be rate-limited.
3. Fixed Window Counter algorithm
Fixed window is one of the most basic rate-limiting mechanisms and probably the simplest technique for implementing rate limiting.
We keep a counter for a given duration of time and keep incrementing it for every request we get. Once the limit is reached, we drop all further requests till the time duration is reset.

Algorithm:
For each request a user makes,
- Check if the user has exceeded the limit in the current window.
- If the user has exceeded the limit, the request is dropped
- Otherwise, we increment the counter
Space Complexity: O(1) for storing the count for the current window.
Time Complexity: O(1) to get a simple atomic increment operation.
Pros:
- Memory efficient.
- Easy to understand.
- Best for use cases where quota is reset only at the end of the unit time window. For example: if the limit is 10 requests/min, it allows 10 requests in every unit minute window say from 10:00:00 AM to 10:00:59 AM, and the quota resets at 10:01:00 AM. It does not matter if 20 requests were allowed in between 10:00:30 AM and 10:01:29 AM, since 10:00:00 AM to 10:00:59 AM is one slot and 10:01:00 AM to 10:01:59 AM is another slot, even though 20 requests we allowed in last one minute at 10:01:30 AM. This is why this algorithm is called a Fixed Window and not a Sliding Window.
Cons:
- A spike in traffic at the edge of a window makes this algorithm unsuitable for use cases where the time window needs to be tracked in real-time at all given times.
Example 1: if we set a maximum of 10 messages per minute, we don’t want a user to be able to receive 10 messages at 0:59 and 10 more messages at 1:01.
Example 2: if the limit is 10 requests/min and 10 requests were sent starting from 10:00:30 AM to 10:00:59 AM, then no requests will be allowed till 10:01:29 AM and the quota will be reset only at 10:01:29 AM since 10 requests were already sent in last 1 min starting at 10:00:30 AM.
4. Sliding Window Logs algorithm
As discussed above, the fixed window counter algorithm has a major drawback: it allows more requests to go through at the edge of a window. The sliding window logs algorithms fix this issue.
- The algorithm keeps track of request timestamps. Timestamp data is usually kept in a cache, such as sorted sets of Redis.
- When a new request comes in, remove all the outdated timestamps. Outdated timestamps are defined as those older than the start of the current time window.
Storing the timestamps in sorted order in sorted set enables us to efficiently find the outdated timestamps. - Add the timestamp of the new request to the log.
- If the log size is the same or lower than the allowed count, a request is accepted. Otherwise, it is rejected.

Implementation:
Whenever a request arrives, the Sliding Window Logs algorithm would insert a new member into the sorted set with a sort value of the Unix microsecond timestamp. This would allow us to efficiently remove all of the set’s members with outdated timestamps and count the size of the set afterward. The sorted set’s size would then be equal to the number of requests in the most recent sliding window of time.
Algorithm:
For each request a user makes,
- Check if the user has exceeded the limit in the current window by getting the count of all the logs in the last window in the sorted set. If the current time is 10:00:27 and the rate is 100 req/min, get logs from the previous window(10:00:27–60= 09:59:28) to the current time(10:00:27).
- If the user has exceeded the limit, the request is dropped.
- Otherwise, we add the unique request ID (you can get from the request or you can generate a unique hash with userID and time) to the sorted sets(sorted by time).
Space Complexity: O(number of buckets)
Time Complexity: O(1)
Pros:
- works flawlessly and accurately. In the rolling window, requests will not exceed the rate limit.
Cons:
- consumes a lot of memory because even if a request is rejected, its timestamp will still be stored in memory.
Thanks for reading.
#NeverEndingImprovement
reference:

{kind=link}
{kind=link}
{kind=link}
{kind=link}